
Securing Data Pipelines: Privacy, Compliance, And Security-by-Design On AWS

This Blog Post is part of Building and Securing Data Pipelines: From Governance to Secure Implementation Series
A practical guide for engineers and managers to design secure, compliant data pipelines — from governance basics to production-grade implementation.
In the cloud, speed and scalability mean nothing if you can’t protect the data you process. Regulations like GDPR don’t just demand encryption — they require security and privacy to be embedded at every stage of the data lifecycle.
In this final post of our “Building and Securing Data Pipelines” series, we’ll dive into the security pillars, privacy laws, and technical safeguards that make an AWS DLP pipeline both production-ready and compliant. You’ll see how to apply these principles from ingestion to archival — without leaving compliance to chance.
Read the full series:
- Blog 1: Data Governance for Engineers: The 5 Pillars Every Secure Pipeline Needs
- Blog 2: Designing a Data Pipeline Architecture That Embeds Governance & Security
- Blog 3: Mapping Data Governance to AWS: Building a Secure DLP Pipeline
- Blog 4: Securing Data Pipelines: Privacy, Compliance, and Security-by-Design on AWS (you are here)
Understanding Security Pillars - CIA Triad
The CIA Triad stands for Confidentiality, Integrity, Availability:
- Confidentiality - Ensures that only authorized individuals or systems can view or access the data
- Integrity - Ensures that data remains accurate, complete, and trustworthy. It prevents unauthorized modification, deletion, or corruption of data
- Availability - Available data is readily accessible to authorized parties when they need it
There are two additional pillars:
- Authenticity - Ensures that a person or system is authentic and we can verify that
- Non-repudiation - Ensures that someone cannot deny responsibility or deny the validity of their actions or data they generated
Data protection & safety deals with implementing these pillars to safeguard data against unauthorized access, modification, or loss while ensuring compliance with privacy laws.
Understanding Data Privacy Requirements
Data privacy deals with laws and regulations which an organization needs to follow to avoid fines/penalties.
Let’s take an example of General Data Protection Regulation (GDPR) which is a European Union law focused on data protection and privacy.
We can break it down into three buckets:
Data Collection and Processing
- Data minimization
- Purpose limitation
Data Subject Rights
- Right to access
- Right to erase
Data Protection
- Data breach notifications
- Encryption of data
We can develop our understanding as follows:
- GDPR is applicable inside EU or outside EU enforced by EU
- It is about protecting personal data / human rights
- It applies to all the organizations who deals with EU citizens data
- Penalty is $10M or 4% annual revenue
Reference: GDPR Checklist
We want to protect PII data.
Merging Security & Privacy into the Data Lifecycle
Lifecycle stages: Create → Store → Use → Share → Archive → Destroy
For each stage, data must be:
- Classified by sensitivity
- Protected with appropriate security controls
- Managed under compliance requirements
Core Security Strategies/Technologies:
- Encryption and key management (Encrypt data at rest and data in transit)
- Hashing
- Access Management (IAM) / Access Controls
- Data Obfuscation
- Data masking
- De-identification (Anonymization and Pseudonymization)
- Tokenization
- Monitoring (Auditing, logging, traceability)
- Network/Endpoint security
Applying Security-by-Design to Our AWS DLP Pipeline
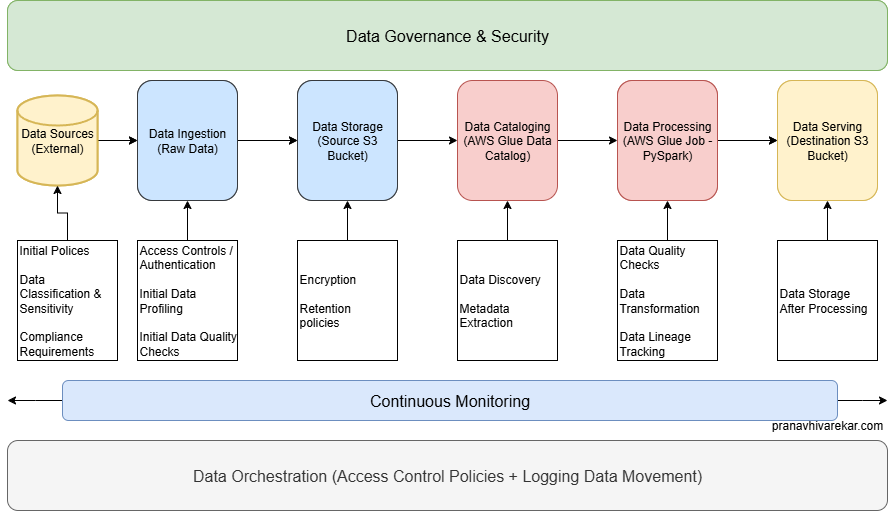
Stage 1 – Data Sources (External)
Before ingestion: Apply organizational data classification, privacy policies, and security standards.
Outcome: Know exactly what’s sensitive (e.g., PII) before it enters the pipeline.
Stage 2 – Data Ingestion & Storage (Source S3 Bucket)
Initial profiling + basic data quality checks
Security controls:
- Encryption at rest (S3 SSE)
- IAM policies for least privilege
- Logging & monitoring (CloudTrail, S3 access logs)
- Network-level protections (VPC endpoints)
Stage 3 – Data Cataloging (AWS Glue Data Catalog)
Formal discovery & metadata extraction
Link classification tags to schema metadata for policy-driven processing.
Stage 4 – Data Processing (AWS Glue ETL with PySpark)
Apply anonymization/redaction logic to sensitive fields.
Security controls:
- IAM roles for Glue jobs
- Fine-grained logging of processing steps
- Processing in private subnets for isolation
Stage 5 – Data Serving (Destination S3 Bucket)
Store sanitized data for consumption.
Security controls:
- Encryption at rest & transit
- IAM role-based access
- Retention & archival policies
- Automated deletion after retention period
Conclusion
Security and privacy aren’t “add-ons” — they’re foundational layers of modern data pipelines.
This AWS DLP architecture demonstrates:
- Security-by-design from ingestion to serving
- Compliance alignment with GDPR & similar regulations
- Practical implementation of data governance in an engineering context
By embedding privacy principles + security controls into every stage, we protect sensitive data before, during, and after processing — making this pipeline not only production-ready but regulation-ready.
This concludes our series on building and securing data pipelines — from governance fundamentals to AWS implementation and security-by-design.
Missed a post? Start from the beginning:
- Blog 1: Data Governance for Engineers: The 5 Pillars Every Secure Pipeline Needs
- Blog 2: Designing a Data Pipeline Architecture That Embeds Governance & Security
- Blog 3: Mapping Data Governance to AWS: Building a Secure DLP Pipeline
- Blog 4: Securing Data Pipelines: Privacy, Compliance, and Security-by-Design on AWS (you are here)



