
Mapping Data Governance To AWS - Building a Secure DLP Pipeline

This Blog Post is part of Building and Securing Data Pipelines: From Governance to Secure Implementation Series
A practical guide for engineers and managers to design secure, compliant data pipelines — from governance basics to production-grade implementation.
A well-designed data pipeline is more than just moving data — it’s about governance, security, and trust. I took the initial generic blueprint for a governed data pipeline and turned it into a fully working AWS implementation that automatically identifies and redacts sensitive data.
Companies often have security policies on paper but no enforcement in the pipeline itself. If sensitive data slips past ingestion, it can land in non-secure systems, creating compliance and legal risks. The challenge was to embed governance and data loss prevention (DLP) directly into the pipeline — without slowing down the data flow.
This project is an AWS Glue + PySpark pipeline that automatically identifies and redacts sensitive data before it moves further downstream. It is available on GitHub.
Read the full series:
- Blog 1: Data Governance for Engineers: The 5 Pillars Every Secure Pipeline Needs
- Blog 2: Designing a Data Pipeline Architecture That Embeds Governance & Security
- Blog 3: Mapping Data Governance to AWS: Building a Secure DLP Pipeline (you are here)
- Blog 4: Securing Data Pipelines: Privacy, Compliance, and Security-by-Design on AWS
From Blueprint to Implementation
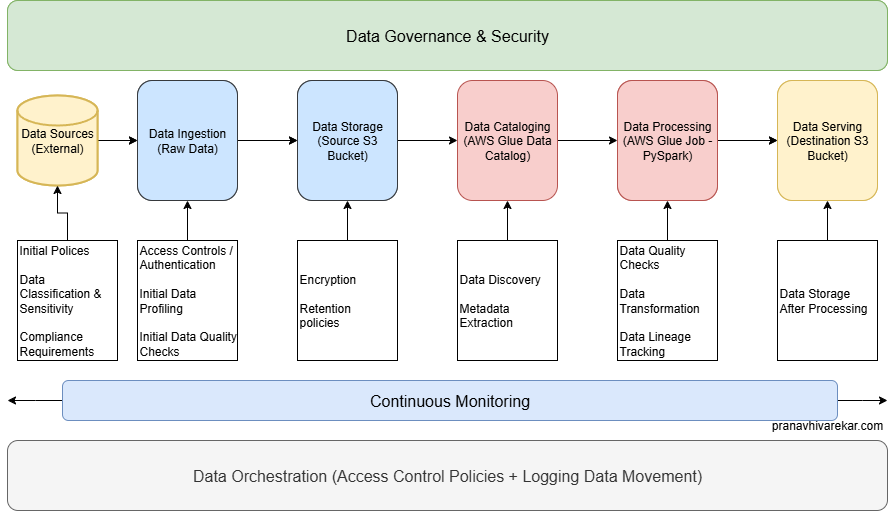
This is how we use blueprint architecture and design our data pipeline. Let’s break down each component and build our understanding.
Data Sources (External)
- Identify source trustworthiness
- Apply policies for data acquisition and licensing
- Have data classification and sensitivity defined for your organization
- Verify compliance with jurisdictional rules (data residency, cross-border transfer laws)
Data Ingestion (Raw Data)
- Enforce access control and authentication for source systems
- Perform initial data profiling to understand the data
- Apply initial data quality checks and metadata tagging
Data Storage (Source S3 Bucket)
- Implement encryption at rest
- Apply data classification labels
- Define retention rules in line with governance policy
Data Cataloging (AWS Glue Data Catalog)
- Perform data discovery
- Extract Metadata
Data Processing (AWS Glue Job - PySpark)
- Perform data transformation (redaction in our case)
- Maintain data lineage tracking for auditability
- Validate outputs against quality rules
Data Serving (Destination S3 Bucket)
- Implement encryption at rest
- Storing data after processing
Data Orchestration
- Ensure workflows respect access control policies
- Log all data movement for traceability
- Trigger governance checkpoints automatically
Data Governance & Security
- Use continuous monitoring for compliance and security incidents
- Integrate governance tools with data catalog and DLP solutions
Technical Implementation
Please review the GitHub project for minute technical details and code on how the pipeline is implemented.
Conclusion
This implementation transforms the blueprint into a production-ready pipeline. It’s modular enough to extend with new governance checks — for example, archiving raw data for long-term compliance or rejecting poor-quality data and reprocessing it automatically.
With this approach, we are successfully integrating governance and security right from the start, just like shift-left in DevSecOps. Whether you’re handling sensitive healthcare records or financial transactions, the same principles and code structure can be adapted to protect data at every stage.
In Blog 4, we’ll go deeper into security-by-design and privacy requirements, breaking down the controls that make this pipeline not just production-ready, but also regulation-ready.
Read Part 4: Securing Data Pipelines: Privacy, Compliance, and Security-by-Design on AWS →



