
Designing A Data Pipeline Architecture That Embeds Governance & Security

This Blog Post is part of Building and Securing Data Pipelines: From Governance to Secure Implementation Series
A practical guide for engineers and managers to design secure, compliant data pipelines — from governance basics to production-grade implementation.
Understanding governance principles is one thing — embedding them into your data pipeline is another.
Many organizations have written policies, but the architecture itself leaves gaps where sensitive data can slip through unnoticed. It’s like having a security checklist for your house but forgetting to put locks on the back doors. The intent is there, but the design leaves you exposed.
In this post, we’ll take the five pillars of governance from Blog 1 and show how to integrate them into a generalized pipeline architecture — stage by stage — so your design is secure and compliant from day one.
Read the full series:
- Blog 1: Data Governance for Engineers: The 5 Pillars Every Secure Pipeline Needs
- Blog 2: Designing a Data Pipeline Architecture That Embeds Governance & Security (you are here)
- Blog 3: Mapping Data Governance to AWS: Building a Secure DLP Pipeline
- Blog 4: Securing Data Pipelines: Privacy, Compliance, and Security-by-Design on AWS
A Simple Data Pipeline With Data Governance & Security
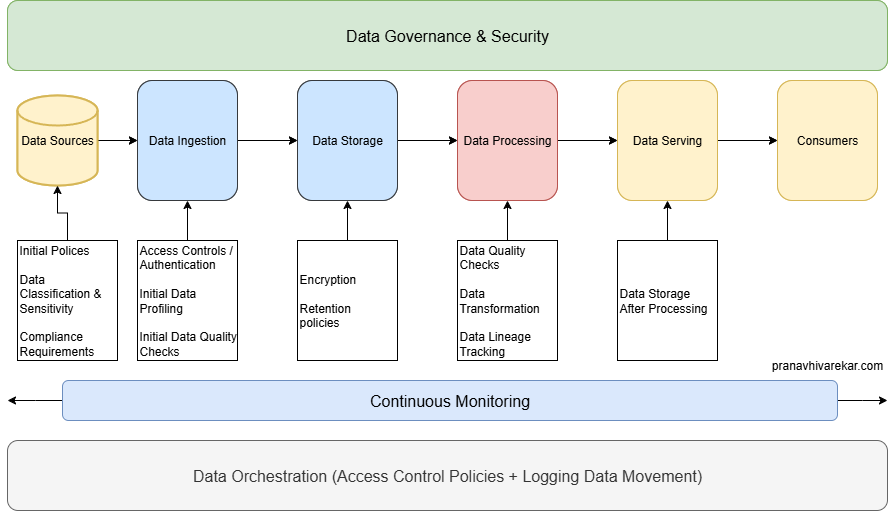
This is a simple data pipeline. Following are the components:
- Data Sources
- Data Ingestion
- Data Storage
- Data Processing
- Data Serving
- Data Orchestration
Data Governance & Security should be integrated in every step of the pipeline.
Applying Governance Across the Pipeline
Data Sources
- Identify source trustworthiness
- Apply policies for data acquisition and licensing
- Have data classification and sensitivity defined for your organization
- Verify compliance with jurisdictional rules (data residency, cross-border transfer laws)
Data Ingestion
- Enforce access control and authentication for source systems
- Perform initial data profiling to understand the data
- Apply initial data quality checks and metadata tagging
Data Storage
- Implement encryption at rest
- Apply data classification labels
- Define retention rules in line with governance policy
Data Processing
- Perform data transformation
- Maintain data lineage tracking for auditability
- Validate outputs against quality rules
Data Serving
- Storing data after processing
Data Orchestration
- Ensure workflows respect access control policies
- Log all data movement for traceability
- Trigger governance checkpoints automatically
Data Governance & Security
- Use continuous monitoring for compliance and security incidents
- Integrate governance tools with data catalog and DLP solutions
How Governance & Security Fit Together?
Policies & Standards → Security Policy & Regulatory Compliance
Ownership & Accountability → Access Control & Audit Logging
Data Quality → Integrity Assurance
Data Protection & Safety → CIA Triad + Privacy
Data Use & Availability → Controlled Access + Availability SLAs
Data Management (Lifecycle) → Secure Retention & Disposal
Conclusion
This is a simple blueprint for designing and building secure data pipelines which integrates all the pillars of data governance into each stage of the data pipeline and reinforces them with strong security practices.
In Blog 3, we’ll map this architecture to a real AWS implementation that automatically detects and protects sensitive data — turning our blueprint into a working, production-ready pipeline.
Read Part 3: Mapping Data Governance to AWS: Building a Secure DLP Pipeline →



