
Data Governance For Engineers - The 5 Pillars Every Secure Data Pipeline Needs

This Blog Post is part of Building and Securing Data Pipelines: From Governance to Secure Implementation Series
A practical guide for engineers and managers to design secure, compliant data pipelines — from governance basics to production-grade implementation.
Most data engineers focus on moving data from point A to point B — fast. But in today’s compliance-heavy world, speed without governance is a liability.
Weak or missing governance can trigger breaches, regulatory fines, and a loss of customer trust. Think about a pipeline that ingests sensitive data without proper access controls or encryption. It works fine… until an auditor shows up or a breach happens. Suddenly, that “fast” pipeline becomes your biggest problem.
That’s why this post — the first in our “Building and Securing Data Pipelines” series — breaks down the five pillars of data governance in a way engineers can actually implement. By the end, you’ll know exactly what governance looks like in practice and why it’s non-negotiable for secure, compliant pipelines.
Read the full series:
- Blog 1: Data Governance for Engineers: The 5 Pillars Every Secure Pipeline Needs (you are here)
- Blog 2: Designing a Data Pipeline Architecture That Embeds Governance & Security
- Blog 3: Mapping Data Governance to AWS: Building a Secure DLP Pipeline
- Blog 4: Securing Data Pipelines: Privacy, Compliance, and Security-by-Design on AWS
A Simple Data Pipeline
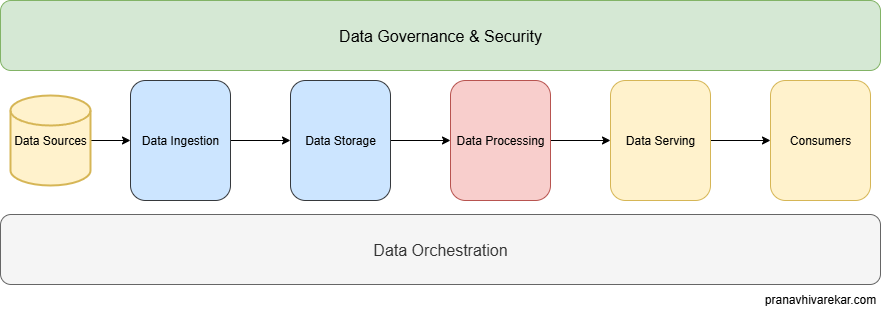
Data pipelines can be of multiple types but let’s stick to ETL Pipelines (Extract, Transform, Load) which are most common and easier to understand. For example, we download/retrieve a PDF from a website then we transform it (process the PDF and get only the required piece of information from it) and then load processed data into a relational database.
There are multiple components in a data pipeline - data sources, data ingestion, data storage, data processing, data orchestration, data governance and security. We will focus on the data governance part and build on our understanding of it.
Data Governance Pillars
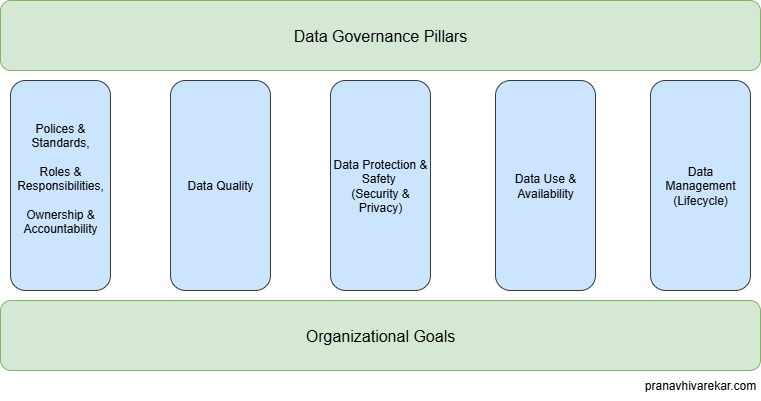
Data governance is a system of rules or a framework ensuring effective management of data assets. It deals with five pillars broadly:
- Policies & Standards, Roles & Responsibilities, Ownership & Accountability
- Data Quality
- Data Protection & Safety (Security & Privacy)
- Data Use & Availability
- Data Management (Lifecycle)
The ultimate aim is to maximize data value while aligning with organizational goals.
Policies & Standards
Policies & standards are created by senior management which defines the high-level principles and detailed rules that guide how data is managed, protected, and used in alignment with laws, regulations, and business objectives.
Remember this:
- Policies define what must be done; standards are mandatory requirements derived to implement policies
- They must integrate compliance requirements (GDPR, HIPAA, PCI DSS)
- They must provide consistency across data handling practices
Policies & Standards allows to create a clear, enforceable framework for secure and compliant data handling.
Roles & Responsibilities
Roles & responsibilities assign duties to individuals or teams to ensure governance activities are executed and enforced.
Remember this:
- Roles and responsibilities should be clearly defined to prevent gaps or overlaps
- Example of roles are Data Owners, Data Stewards, Data Custodians
Roles & Responsibilities allows to reduce risk of mismanagement and ensures accountability.
Ownership & Accountability
Ownership & accountability defines who has decision-making authority over data assets and holds them responsible for governance compliance.
Remember this:
- Accountability and ownership cannot be delegated but responsibilities can
- It ensures someone is answerable if something goes wrong
- Data Owner is ultimately accountable
Ownership & Accountability allows to enforce compliance ownership.
Data Quality
Data quality is all about rules to ensure data is accurate, complete, consistent, timely, valid and fit for its intended use. For example, if a source data contains 5000 records, the same 5000 records should exist after transformation and loading stages, unless intentionally filtered, to meet the completeness criteria. Similarly, other data quality rules can be defined.
Few concepts to remember:
- Metadata - Metadata is data about data. It helps to understand data
- Data Lineage - Data lineage helps to visualize flow of data in a pipeline, from source to destination including all transformation steps
- Data Profiling - Data profiling is the process of examining and analyzing a dataset to understand its characteristics, quality, and structure to identify potential quality issues
Process can be simplified as:
- Define and implement data quality rules (You should know what is good data for you)
- Continuously monitor for data quality issues
- Identify the issue utilizing metadata and data lineage
- Triage and remediate
Poor data quality leads to wrong decisions, compliance risks, and loss of trust.
Data Protection & Safety (Security & Privacy)
Data protection & safety deals with safeguarding data against unauthorized access, modification, or loss while ensuring compliance with privacy laws.
Remember this:
- Security deals with CIA Triad (Confidentiality, Integrity, Availability)
- Data state can be data at rest, data in-transit and data in-use. We need to protect data in each state
- Privacy deals with regulation and laws eg. GDPR. We need to be compliant with every law and regulation to avoid penalties and fines
- Detect data breaches and have incident response plans ready
- Protect data using DLP and IRM tools
Process can be simplified as:
- Classifying the data
- Protecting the data
Data protection & safety deals with protecting both the organization’s assets and customer trust.
Note: We will expand on data security and data privacy in a dedicated blog post of this series
Data Use & Availability
Data use & availability deals with governing how data is accessed, shared, and delivered to authorized users while maintaining performance and compliance.
Remember this:
- Implement access control models to make data only available to the right people
- Have service level agreements for data availability
Data use & availability ensures data is available when needed, but only to the right people.
Data Management (Lifecycle)
Data management deals with data from creation to archival or secure disposal in line with governance rules.
Lifecycle stages: Create → Store → Use → Share → Archive → Destroy
Remember this:
- Design retention policies per regulatory needs
- Data should be securely deleted/destroyed to prevent data leakage
Effective data management helps to avoid unnecessary storage costs, reduces risk, and ensures compliance with retention and disposal requirements.
Conclusion
Data governance isn’t just about rules—it’s about trust, compliance, and enabling better decisions. The five pillars provide the structure, but it’s the consistent execution of these principles that turns data into a true business asset.
Now that you understand the pillars of data governance, the next step is turning those principles into an architecture you can actually build.
Read Part 2: Designing a Data Pipeline Architecture That Embeds Governance & Security →



